
Replication چیست؟
همانطور که می دانیم افراد بسیاری وجود دارند که مشترک مجلات الکترونیکی بوده و یا اخبار روز جهان را از طریق ایمیل خود دریافت می کنند. بنابراین با عضویت و مشترک شدن در این مجلات و mailer ها به سادگی قادر به دریافت اخبار روز و مورد نظر خود هستند. بطور مشابه قابلیت Replication در MS SQL نیز همین نقش را ایفا کرده و داده ها را به عنوان مثال از یک سرور ریموت به Box های سرورهای لوکال از طریق مکانیزم نشرو اشتراک گذاری (publications and subscriptions) انتقال می دهد.
Replication در واقع به مجموعه ای از توپولوژی ها برای کپی و توزیع داده ها و اشیاء و یا Object های پایگاه داده ، از یک پایگاه داده به دیگری و نیز به هماهنگ سازی بین پایگاه های داده برای حفظ انسجام اطلاق می شود. با استفاده از Replication می توانیم داده ها را به مکانهای مختلف ومیان کاربران از راه دور یا ریموت در سراسر شبکه های محلی و نیز گسترده و ارتباطات dial-up وwireless و همچنین در اینترنت ، توزیع کنیم . دلایل و سناریو های مختلفی موجود است که موجب می شود که Replication به عنوان ابزاری قدرتمند برای پخش کردن و انتشار داده ها در نظر گرفته شود . در اینجا به دلایلی برای عمل Replication اشاره خواهیم کرد:
- در نظر گرفتن replication برای از بین بردن اثرات عملیات متمرکز و فشرده ی Read مثل تولید گزارش و… . در واقع replication گزینه ی مناسبی است برای زمانی که اطلاعات مورد نظر read only بوده و نیازی به آپدیت کردن source نداریم.
- در دسترس قرار دادن داده ها برای کاربر، به عنوان مثال سرور ITPro در تهران است و از آنجایی که سازماندهی بخش توزیع ویدیو های آموزشی آن در شهر اهواز صورت می گیرد ، برای چنین سازماندهی ،نیازمند اطلاعات کاملا مرتب هستیم . حال هر بار که ما نیاز به استفاده از داده های مربوط به محصولات و یا جداول فروش داشته باشیم از یک Linked Server برای برقراری ارتباط با سرور تهران و دریافت داده های مورد نظر استفاده خواهیم کرد.چنین شرایطی اثراتی را نیز به دنبال دارد:
- قطعا برای دریافت داده ها در هر زمان شدیدا به ارتباطات شبکه ای متکی خواهیم بود .
- سرور منبع یا همان Source Server نیز Load کاری بالایی را برای خواندن داده ها متحمل خواهد شد .
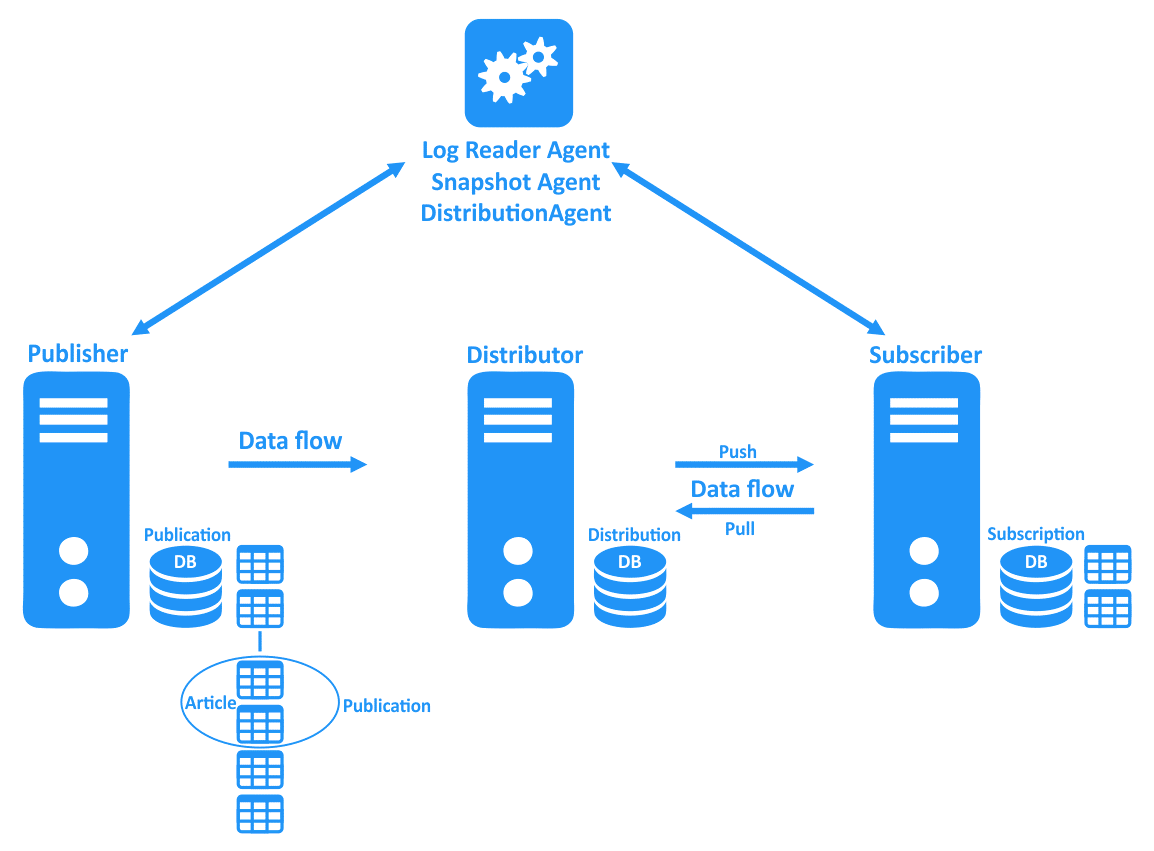
پیش از پرداختن به انواع replication و جزئیات مربوط به نصب آن ابتدا باید با مفهوم چند واژه آشنا شویم . عمل replication به طور سنتی از ساختار publisher//subscriber تبعیت می کند.همانند رابطه ی مشترکین و ناشران مجلات. برای هر مجله یک ناشر (publisher) وجود دارد که اطلاعات را در قالب مقالات (articles) منتشر می کند.
حال این مجله ای که دربردارنده ی مجموعه ای از مقالات است برای انتشار و در اختیار عموم و نیز مشترکان قرار گرفتن نیاز به یک توزیع کننده (distributer) دارد و این یک ساختار استاندارد برای چرخه ی publisher // subscriber محسوب می شود.اما گاها با تغییراتی در این روند نیز مواجه می شویم به عنوان مثال ممکن است که یک publisher به عنوان یک distributer یا توزیع کننده ایفای نقش کند و یا اینکه یک distributer یا توزیع کننده ایفاگر نقش یک subscriber نیز باشد. حال به توضیح هر یک از این واژه های کلیدی می پردازیم :
- Article یا مقاله : به اطلاعاتی اطلاق می شود که قصد replicate آنها را داریم . این اطلاعات می تواند یک جدول یا یک روال یا procedure یا یک جدول فیلتر شده و … را در برگیرد.
- Publication یا نشریه: به گروهی از article ها اطلاق می شود. یک article به تنهایی قادر به انتشار نیست از این رو نیاز به ایجاد publication داریم. به بیان دیگرانتشار یا publication به معنی مجموعه ای از Article ها است (اشیاء مختلف پایگاه داده ) که توسط ناشر منتشر شده است.
- Publisher یا ناشر: به database روی source سرور گفته می شود که در واقع قصد replicate داده های آن را داریم . به عبارت دیگر یک Publisher در واقع یک database Instance است که داده ها ی موجود در طی فرایند Replication به مکان های دیگر را در دسترس قرار می دهد . یک ناشر می تواند یک یا چندین نشریه و هر تعریف منطقی مرتبط با مجموعه ی اشیا و داده هایی برای Replicate را در بر داشته باشد.
- Distributor یا توزیع کننده: یک توزیع کننده را می توان همانند پسر بچه ای در نظر گرفت که مسئولیت تحویل نشریات به مشترکین را به عهده دارد. یک توزیع کننده می تواند ایفا گر نقش ناشر یا مشترک نیز باشد.
- Distribution Database یا پایگاه داده ی توزیع شده : این پایگاه داده دربردارنده ی تمامی خط فرمانهای replication است. زمانی که هرگونه از تغییرات شمای DML یا DDL در Publisher اجرا شود ، دستورات مربوط به این اعمال که توسط SQL سرور تولید می شود ، دراین بخش ذخیره خواهد شد .این پایگاه داده می تواند روی همان سرور Publisher موجود باشد اما معمولا برای عملکرد بهتر توصیه می شود که آن را بر روی یک سرور مجزا قرار دهند. به طور معمول مشاهده شده که اگر distribution database روی همان ماشینی باشد که پایگاه داده ی publisher روی آن قرار دارد ، در صورتیکه تعداد زیادی Publisher موجود باشد ، این موضوع عملکرد سیستم را تحت تاثیر قرار می دهد و این دلیلی است که برای هر Publisher یک فایل distrib.exe ایجاد می شود.
- Subscriber یا مشترک : چرخه ی انتشار با دریافت داده ها توسط یک مشترک پایان می یابد. تغییرات منتشر شده میان تمامی مشترکین یک فرایند انتشار، از طریق یک توزیع کننده تکثیر می شود. بنابراین یک مشترک با اشتراک و عضویت در یک فرایند انتشار در نهایت قادر به دریافت داده ها خواهد بود. به عبارت دیگر Subscriber یک Database Instance است که داده های replicate شده را دریافت می کند و نیز می تواند داده ها را از چندین ناشر (publisher) یا نشریه (publishers) بگیرد. بسته به نوع Replication ای که انتخاب می شود ، یک Subscriber می تواند داده ها را متقابلا به ناشر انتقال داده و یا آنها را برای سایر مشترکین منتشر کند .
- Subscription یا اشتراک : به درخواست یک مشترک یا subscriber برای دریافت نشریه یا publication اطلاق می شود و بر دو نوع است:Pull وPush که در واقع دو روش برای انتقال داده ها از distributor یا توزیع کننده به subscriber ها یا مشترکین محسوب می شوند. در ذیل به شرح آنها می پردازیم :
- Push Subscription: در روش push subscription یک distributor یا توزیع کننده مسئول داده های بر صف از یک publisher بوده و درنهایت آنها را در اختیارsubscriber ها قرار می دهد.این نوع اشتراک مدیریت را ساده و متمرکز می کند چون سناریوی replication معمولی ، یک publisher و چندین subscriber را شامل می شود .مزیت این اشتراک امنیت بالای آن است چرا که فرایند آغازین در یک مکان مدیریت می شود. به عبارت دیگر کارایی distributor ها کاهش می یابد زیرا کل توزیع subscriber ها یک دفعه اجرا می شود.
- Pull subscription: همانند روش push یک distributor یا توزیع کننده داده های بر صف یک publisher بوده و این وظیفه ی subscriber ها است که با distributor ارتباط برقرار کرده و داده های صف بندی شده ی آماده برای عمل replication را به تصرف خود درآورند. در مقایسه با روش push از روش pull برای نشریه هایی با امنیت پایین و تعداد بالای مشترک ها استفاده می شود. این نوع اشتراک رایج تربوده چرا که یک مشترک می تواند publication و یا نشریه هایی را انتخاب کند تا در آن شرکت کند.
شرح replication Agent ها در SQL سرور
حال به توضیح عواملی که برای انجام replication در پشت صحنه فالیت می کنند می پردازیم که Agent نامیده می شوند .این agent ها در فایلهای مربوطه با پسوند exe در مسیر………..\110\COM folder قرار دارند. همچنین تمامی اطلاعات مربوط به agent ها در جداول dbo.MSxxx__agents و dbo.MSxxx__history موجود در Distribution database ثبت شده اند. حال به شرح انواع agent ها و اینکه در کدام نوع از انواع replication کاربرد دارند می پردازیم (برای روشن شدن این مبحث در اینجا اشاره می کنیم که replication در SQL سرور به سه نوع Snapshot و transactional و merge تقسیم می شود که نیازمند Agent ها برای فعالیت خود هستند . در ادامه ی مقاله عناوین ذکر شده شفاف سازی خواهند شد :D) و اما شرح Agent ها :
Snapshot Agent: یک فایل اجرایی است که snapshot فایل های در بردارنده ی شماتیک یا ساختار و داده های جداول و اشیاء پایگاه داده را ایجاد کرده و آنها را در Distributor ذخیره می کند همچنین اطلاعات مربوط به وضعیت synchronization را در distribution database ثبت می کند.
- Distribution Agent: برای انواع snapshot و transactional مورد استفاده قرار می گیرد. و فایل های snapshot را از distribution db به مشترکین انتقال می دهد همچنین تمامی تراکنش های منتظر برای انتشار را نیز به subscriberها منتقل می کند و برای هر دو push subscription و pull subscription قابل اجرا است .
- Log Reader Agent: برای transactional replication استفاده می شود تراکنش های مشخص شده برای replication را از transaction log به distribution db روی publisher انتقال می دهد. هر پایگاه داده ای log reader مختص به خود را دارد که روی distributor اجرا شده و با publisher ارتباط بر قرار می کند.
- Merge Agent: در merge replication کاربرد دارد و snapshot اولیه را برای subscriber ها اجرا کرده و تغییرات تدریجی به وجود آمده روی داده ها را نیز ادغام کرده وبه subscriber ها انتقال می دهد. هر اشتراک ادغامی merge agent خود را دارد که قادر به برقراری ارتباط با publisher و subscriber و به روزرسانی هر دوی آنها می باشد.
- Queue Reader Agent: برای transactional replication کاربرد دارد و بر روی Distributor اجرا شده و تغییرات صورت گرفته در سمت subscriber را به publisher باز می گرداند. برخلاف merge agent وagent distribution تنها یک نمونه از Queue Reader Agent برای سرویس دهی به تمامی publisher ها و publication ها و برای یک distribution db معین وجود دارد.
فیلتر کردن داده های منتشر شده:
فیلتر کردن جداول موجود در article ها ما را قادر می سازد تا پارتیشن هایی از داده ها را برای انتشار ایجاد کنیم .به کمک فیلتر کردن داده های منتشر شده می توان :
- داده های ارسال شده روی شبکه را به حداقل رساند .
- مقدار فضای ذخیره سازی مورد نیازبرای یک مشترک را کاهش داد.
- نشریات یا publication ها را سفارشی سازی کرده و نیز شرایطی را فراهم کرد که application ها بر اساس نیازهای اختصاصی یک مشترک باشند.
- اگر مشترکین داده ها را به روزرسانی کنند ، می توان از بروز conflict ها جلوگیری کرده و یا آنها را کاهش داد زیرا پارتیشن های داده های مختلف می توانند برای مشترکین مختلف ارسال شوند. ( در واقع در این شرایط هیچ دو مشترکی قادر به بروزرسانی داده های مشابه نخواهند بود)
- می توان از انتقال اطلاعات مهم و حساس جلوگیری کرد. فیلتر های ردیف و فیلترهای ستون ها می توانند برای محدود کردن دسترسی مشترک به داده ها مورد استفاده قرار گیرند.
Replication چهار نوع فیلتر را ارائه می دهد که در ذیل به معرفی آنها می پردازیم :
- Static row filter ها یا فیلتر کردن ردیف ها به صورت استاتیک که برای تمامی انواع replication ازقبیل snapshot و transactional و merge کاربرد دارد . با استفاده از آن قادر خواهیم بود زیر مجموعه ای از ردیف هایی را که منتشر می شوند ،انتخاب کنیم و یا در واقع بر حسب نیازمان آنها را محدود کنیم .
- Column filter یا فیلتر کردن ستون که این نوع فیلتر نیز برای تمامی انواع replication به کار می رود و به کمک آن می توان زیرمجموعه ای از ستونهایی را که منتشر می شوند، انتخاب کرد.
- Parameterized row filtered یا فیلترهای پارامتری ردیف ها تنها برای merge replication به کار گرفته می شود . این نوع از فیلتر از نظر مفهوم همانند static filter است اما در اجرا تفاوت قابل توجهی با یکدیگر دارند .هدف parameterized filter ایجاد چندین پارتیشن از داده ها است که بدون ایجاد چندین نشریه یا publication بتوانند replicate داشته باشند. به عنوان مثال اگر ما از جدول پایه ی یکسانی استفاده کنیم و دو مشترک مختلف به نام های A و B نیز داشته باشیم که هر کدام به زیر مجموعه هایی متفاوتی از آن جدول نیاز داشته باشند ، هنگام استفاده از فیلترهای ردیفی استاندارد نیازمند ایجاد دو نشریه یکی برای مشترک A و دیگری برای مشترک B خواهیم بود .اما با استفاده از فیلتر های پارامتری می توانیم برای مشترکین A و B به صورت مجزامقادیر مورد نظر متفاوتی را در نظر بگیریم. اما در نهایت هر یک از این مقادیر و مجموعه داده ها به عنوان بخشی از یک نشریه محسوب می شوند.
- Join filter یا فیلتر الحاق که تنها برای merge replication کاربرد دارد و این نوع فیلتر به طور معمول همراه با parameterized filter ها برای بسط وگسترش فیلترینگ به دیگرجداول مربوطه به کار می رود. مثلا یک نمایندگی فروش معمولا داده های جداول دیگر از قبیل مشتریان و دیگر جداول را دارد .این دادها می توانند فیلتر شده باشند به طوری که نماینده فروش تنها داده های مشتریان خود و سفارشات آنها را دریافت کند. این نوع فیلتر همچنین می تواند همراه با static filter ها نیز به کار گرفته شود.
توپولوژی هایی که MS SQL سرور برای انجام Replication آنها را پشتیبانی می کند:
Central Publisher : این یکی از پر کاربردترین نوع توپولوژی ها است که در replication مورد استفاده قرار می گیرد .در این سناریو یک سرور به عنوان publisher و distributor منظور شده و سرور و یا سرور های دیگر به عنوان subscriber ها در نظر گرفته می شوند.
Publishing Subscriber : این توپولوژی دارای نقشی دوگانه است . در این ساختار دو سرور داده های یکسان را منتشر می کنند. یکی از سرورهایی که عهده دار نقش publisher است داده ها را برای subscriber ارسال کرده و سپس subscriber داده ها را برای هر تعداد از مشترکین موجود منتشر می کند. این توپولوژی هنگاهی کاربرد دارد که یک publisher قصد انتقال داده ها را از طریق لینکهای ارتباطی کُند و یا گران قیمت به subscriber ها داشته باشد.
انواع Replication
انواع replication ای که در SQL Server 2008R2 صورت می گیرند به قرار زیر است :
- Transactional Replication یا رونوشت تراکنش
- Merge Replication یا رونوشت ادغامی
- Snapshot replication یا رونوشت ثبت لحظه ای
نوع replication ای که ما انتخاب می کنیم به فاکتورهای مختلفی وابسته است این فاکتورها محیط فیزیکی replication ، نوع و کمیت داده هایی که قصد replicate آنها را داریم و اینکه آیا داده ها باید برای subscriber به روز رسانی شوند یا خیر را شامل می شود. محیط فیزیکی به تعداد و مکان کامپیوتر های درگیر در عمل replication اطلاق می شود .حال این کامپیوترها می توانند client هایی همچون workstation ها ، لپ تاپ ها و یا device های handle بوده و یا سرور ها را در بر گیرند.
هر نوع از replication بطور معمول با همگام سازی اولیه ی object های publish شده میان publisher و subscriber شروع می شود. این همگام سازی اولیه می تواند توسط replication و با یک snapshot ایجاد شود. Snapshot یک کپی از تمامی object ها و داده های مشخص شده توسط یک نشریه یا publication تهیه می کند.پس از اینکه snapshot ایجاد شد ، به مشترکین یا subscriber ها تحویل داده می شود.
برای برخی از نرم افزارهای کاربردی snapshot replication مورد نیاز می باشد و برای دیگر application ها این مساله مهم است که تغییرات ایجاد شده روی داده ها بصورت تدریجی در طول زمان در اختیار Subscriber قرار بگیرد.برخی از Application ها نیازمند بازگشت تغییرات صورت گرفته روی داده از از subscriber به publisher نیز هستند . transactional replication و merge replication آپشن هایی هستند که این امکان را برای اینگونه application ها فراهم می آورند. تغییرات صورت گرفته روی داده ها ، از طریق snapshot قابل پیگیری نیست و هر زمان که یک snapshot گرفته شده تایید شود ، روی داده ی موجود overwrite خواهد شد. در transnational replicationپیگیری تغییرات از طریق transaction log های SQL Server و در merge replication نیز از طریق trigger ها و metadata table ها میسر خواهد بود . حال به شرح هرکدام از انواع replication می پردازیم :
Snapshot Replication یا رونوشت ثبت لحظه ای
داده ها را دقیقا همانگونه که در یک لحظه ی خاص زمانی ظاهر می شوند توزیع می کند . و نمی توان بواسطه ی آن آپدیت و به روز رسانی داده ها را مانیتور کرد.وقتی که عمل synchronization اتفاق می افتد Snapshot تولید شده و برای subscriber ها ارسال می شود . باید این نکته را در نظر داشت که Snapshot Replication به خودی خود مورد استفاده قرار می گیرد اما فرایند پردازش snapshot ها که در واقع مراحل کپی برداری از object ها و داده های تعیین شده توسط یک نشریه را نیزشامل می شود ومعمولا برای فراهم آوردن مجموعه ی اولیه ای از داده ها و object های پایگاه داده برای انواع transactional /merge replication کاربرد دارد.استفاده از snapshot replication به خودی خود هنگاهی مناسب است که موارد عنوان شده در ذیل محقق باشند:
- داده ها به ندرت تغییر داشته باشند
- قصد replicate کردن حجم کمی از داده ها را داشته باشیم .
- اگر که حجم زیادی از داده ها در طی یک دوره کوتاه زمانی تغییر کند.
مناسب ترین زمان برای استفاده از snapshot replication هنگامی است که تغییراتی اساسی و قابل توجه اما نادر برای داده ها اتفاق بیفتد. برای مثال اگر لیست قیمت محصولات موجود در فروشگاه ITPro ثابت بوده و یک یا دوبار درسال در یک زمان مشخص آپدیت و به روزرسانی می شوند ، در چنین وضعیتی استفاده از snapshot replication بعد از اعمال تغییرات روی داده ها توصیه می شود با توجه به انواع خاصی از داده ها ، ممکن است که Snapshot های مکرری نیاز باشد.
مثلا اگر یک جدول نسبتا کوچک در سرور publisher در طی روز آپدیت شده اما اندکی تاخیر نیز جایز باشد ، این تغییرات می توانند به عنوان یک Snapshot شبانه تحویل داده شوند. Snapshot replication دارای سربار مداوم کمتری نسبت به transactional replication بر روی publisher می باشد چرا که تغییرات تدریجی را دنبال نمی کند. با این حال اگر مجموعه داده ای که درحال replicate است بسیار بزرگ باشد به منابع قابل توجهی برای ساخت و به کار بردن snapshot نیاز دارد. هنگام ارزیابی شرایط برای استفاده از snapshot replication باید اندازه ی کل مجموعه داده ها و فراوانی تغییرات ایجاد شده روی آنها را در نظر گرفت .
Snapshot replication چگونه کار می کند؟
بطور پیش فرض هر سه نوع replication ازیک snapshot برای مقدار دهی اولیه به subscriber ها استفاده می کنند . همیشه Snapshot agent موجود در SQL Server وظیفه ی تولید فایل های snapshot را به عهده دارد اما agent مربوط به ارائه و تحویل این فایل ها بسته به نوع replication انتخاب شده ، متفاوت است. Snapshot replication و transactional replication برای ارائه ی فایلها از distribution agent استفاده می کنند در حالی که merge replication برای این منظور از merge agent بهره می گیرد. Snapshot agent روی distributor اجرا می شود . distribution agent و Merge Agent روی یک Distributor برای push subscription ها اجرا شده و همچنین بر روی subscription ها برای pull subscriber ها اجرا می شوند.
Snapshot می تواند بلافاصله بعد از ایجاد یک subscription ، تولید و اعمال شود و یا اینکه بر اساس یک برنامه در زمان انتشار ساخته شود. Snapshot Agent فایلهای snapshot حاوی ساختار و داده ها ی جداول منتشر شده (published tables) و نیز اشیاء پایگاه داده را آماده کرده و این فایلها را برای ناشر یا publisher در Snapshot folder ذخیره می کند و مسیر ردیابی این اطلاعات را در Distribution database موجود در Distributor ثبت می کند. می توان snapshot folder پیش فرض را به هنگام پیاده سازی و پیکربندی یک Distributor مشخص کنیم اما می شود که محل دیگری نیز برای نشریه، به جای آن فولدر یا علاوه بر آن فولدر پیش فرض در نظر گرفت.
علاوه بر فرایند snapshot استاندارد که به توضیح آن پرداختیم ، یک فرایند دو بخشی snapshot نیز وجود دارد که در انتشار به صورت ادغام کاربرد دارد که از parameterized filter ها بهره می برد . همانگونه که قبلا گفتیم یک filter فرایندی است که اطلاعات را محدود و یک زیر مجموعه را تولید می کند.استفاده از parameterized filter به ما این اجازه را می دهد که پارتیشن های مختلفی از داده ها را برای subscriber های متعدد ارسال کنیم بدون اینکه نیاز به ایجاد publication ها و یا همان نشریه های متعدد باشد .در تصویر زیر اجزای اصلی Snapshot replication نمایش داده شده که به درک بهتر مفاهیم گفته شده کمک خواهد کرد :
Transactional Replication یا رونوشت تراکنشی
عملیات transactional replication به طور معمول با گرفتن یک snapshot از اشیا و داده های پایگاه داده ی یک publication شروع می شود.به محض اینکه Snapshot اولیه گرفته شد ، تغییرات بعدی که روی داده ها و شماهای موجود در سمت ناشر یا publisher ایجاد شده به subscriber ها تحویل داده می شوند . به طور جزئی تر می توان گفت که تغییرات و تراکنش هایی که روی article های منتشر شده رخ داده اند از سمت publisher برای distributor ارسال می شود تا آنها را برای subscriber ها و یا همان مشترکین بفرستد . subscriber ها تنها می توانند از این داده ها به صورت read only استفاده کنند چرا که در این نوع replication ، تغییراتی که صورت می گیرد مجددا برای publisher بازگردانده نمی شود. با این حال transactional replication آپشن هایی ارائه می دهد که شرایط به روز رسانی اطلاعات را برای Subscriber ها فراهم می آورند .
قطعا عنوان کردن یک مثال مساله را روشن تر می کند : یک وب سایت رزرو بلیط را در نظر می گیریم تمامی بلیط های رزرو شده به صورت متمرکز در پایگاه داده ی واقع در شهر تهران ذخیره می شوند و در هر شهر از کشور نیز یک مرکز توزیع یا distribution center قرار دارد که رزرو ها را گرفته و بلیط های رزرو شده را برای آدرس های موجود ارسال می کند.لازم است که تمامی بلیط های رزرو شده از اهواز برای مشتریان مربوطه ارسال شوند. پایگاه توزیع مرکزی موجود در اهواز می تواند که یک transnational replication فیلتر شده را راه اندازی کند برای اینکه هر رزرو جدیدی (تراکنشی) که صورت گرفت با سایر شعب مربوط به این مرکز، در حداقل زمان ممکن replicate شود. ( فیلتر موجب می شود که این مرکز تنها رزرو ها را برای اهواز دریافت کند ) . این شعب نیازمند دسترسی read only برای استفاده از داده های replicate شده هستند که transnational replication این امکان را برای آنها فراهم می آورد .بنابراین مواردی را می شود برای transactional replication به خاطر سپرد:
- از آنجایی که عمل replication در طی یک تراکنش اتفاق می افتد ، تاخیر تکرار و replicate داده ها بسیار ناچیز است.
- مشترکین دسترسی read only به داده ها دارند ، از این رو تقریبا هیچ گونه استقلالی برای مشترکین یا subscribe ها وجود ندارد.
Transactional replication بطور معمول برای محیط های سرور به سرور(server-to-server) استفاده می شود و برای هر یک از موارد زیر مناسب است :
- زمانی که بخواهیم تغییرات تدریجی داده های مورد نظر را پس از وقوع برای مشترکین منتشر کنیم .
- برای application هایی که به تاخیر کمی بین زمانی که یک تغییر در سمت ناشر ایجاد می شود تا زمانی که تغییر به یک مشترک می رسد نیاز دارند.
- هنگامیکه publisher دارای حجم بسیار بالایی از فعالیت ها از قبیل درج ، به روزرسانی و یا حذف باشد .
- برای زمانیکه Publisher یاSubscriber پایگاه داده ای غیر از SQL سرور باشد .مثلا Oracle باشد.
- یک Application نیاز به دسترسی برای مداخله در وضعیت داده ها داشته باشد برای مثال اگر ردیفی از یک جدول پنج بار تغییر کند ، Transactional Replication به هر Application این امکان را می دهد که قادر باشد برای هر تغییر مداخله کند (مثلا استفاده از trigger ها ) و تغییرات داده ها به سادگی به ردیف ها اعمال نشوند.

Transactional Replication چگونه کار می کند؟
برای پیاده سازیtransactional replication عواملی مانند Snapshot Agent و Log Reader Agent و Distribution Agent ها دخیل هستند . Snapshot Agent درواقع snapshot فایلهای دربردارنده ی ساختارها (schema) و داده های جداول منتشر شده و اشیاء پایگاه داده را مهیا کرده و این فایلها را در فولدر Snapshot ذخیره می کند و نتیجه ی عمل synchronization را در Distribution database موجود روی Distributor ثبت می کند.
Log Reader Agent وظیفه ی مانیتور کردن transaction log های هر پایگاه داده ای که برای عمل transactional replication پیکربندی شده را به عهده داشته و تراکنش های مشخص شده برای عمل replication را از transaction log به distribution database کپی می کند. Distribution Agent نیز Snapshot فایلهای اولیه از پوشه ی snapshot و همچنین تراکنش های نگه داشته شده در جداول distribution database را برای مشترکین یا subscriber ها کپی می کند.
تغییرات تدریجی ایجاد شده سمت ناشر مطابق برنامه زمانبندی Distribution Agent در دسترس مشترکین قرار می گیرند که این جریان انتقال اطلاعات می تواند به طور مداوم با حداقل زمان تاخیر و یا در فواصل زمانی برنامه ریزی شده اجرا شود. از آنجا که تغییرات داده ها باید در سمت ناشر ایجاد می شوند. ( زمانیکه از transactional replication بدون آپشن های immediate updating و queued updating بهره می گیریم . { البته در ادامه به شرح کارایی این دو آپشن می پردازیم } ) باید ازایجاد conflict در به روزرسانی ها جلوگیری کرد .در نهایت تمامی مشترکین به مقادیر مشابه و یکسان از یک ناشر دست خواهند یافت. همچنین اگر از آپشن های immediate updating یا queued updatingبرای transactional replication بهره بگیریم ، به روزرسانی ها می توانند سمت مشترکین ایجاد شوند و با queued updating ، ممکن است تضاد و conflict اتفاق بیفتد.
Immediate Updating به مشترکین Snapshot // Transactional Replication اجازه می دهد تا داده های replicate شده را در سمت مشترک بروزرسانی کرده و تغییرات به وقوع پیوسته را به ناشر و دیگر مشترکین بازگردانی کند . این آپشن برای زمانی مفید است که قصد استفاده از Snapshot یا transactional replication را داشته باشیم اما نیازمند شرایطی باشیم که به روزرسانی های گاه به گاه در سمت مشترک صورت گیرد. برای استفاده از این آپشن ،ناشر و مشترک باید در دسترس بوده و ارتباط بین آن دو برقرار باشد.
Queued Updating به مشترکین Snapshot // Transactional Replication نیز اجازه می دهد داده های منتشر شده را بدون نیاز به یک اتصال شبکه ای اکتیو به publisher ، تغییر دهند. وقتی که یک نشریه یا publication را با استفاده از این آپشن ایجاد می کنیم و یکی از مشترکین عملیاتی چون Insert یا Update یا Delete را روی داده های منتشر شده پیاده سازی می کند ، این تغییرات دریک صف ذخیره می شوند. هنگامی که ارتباطات شبکه ای مجددا برقرار شود ، این تراکنش های بر صف به صورت غیر همزمان به publisher اعمال می شوند.
از آنجایی که که به روزرسانی داده ها به طور غیر همزمان برای publisher منتشر می شوند ، همان داده ها ممکن است توسط خود ناشر یا publisher و یا مشترک دیگری نیز آپدیت شده باشند در نتیجه به هنگام اعمال آپدیت های برصف ممکن است conflict یا ناسازگاری به وجود بیاید. این conflict ها به کمک conflict resolution policy که به هنگام ایجاد یک publication تنظیم می شود ،شناسایی و حل و فصل می شوند .Queued updating برای Application هایی مناسب است که کاربران آنها اغلب داده ها را خوانده و گاه به گاه به به روز رسانی داده ها می پردازند. ارتباطات مشترکین نیز باید اکثر اوقات بر قرار باشد و اگر که مشترکین آقلاین باشند نیز عملیات به روزرسانی بدون وقفه ادامه خواهد یافت.
نکته: این آپشن ها قابلیت سوییچ شدن روی یکدگیر را دارند به عنوان مثال برای Subscription مشخص کرده ایم که از حالت immediate updating استفاده کند ، اما فرضا تحت شرایطی ارتباطات شبکه دچار مشکل شده بنابراین می توانیم برای دریافت آپدیت ها روی queued updating سوییچ کنیم . باید در نظر داشت که replication به صورت اتوماتیک نمی تواند بین حالات آپدیت سوییچ کند و برای این منظور باید تنظیمات مربوط به update mode از طریق SQL Server Management Studio انجام شود و یا application ما sp_setreplfailovermode را برای سوییچ بین دو حالت فراخوانی کند. (این روال به ما اجازه می دهد تا تنظیمات مربط به failover را برای مشترکین یا subscriber ها انجام دهیم تا قادر به تعویص وضعیت از حالت immediate updating به Queued updating باشند.) نحوه عملکرد transactional replication در تصویر زیر نمایش داده شده است:

Merge Replication یا رونوشت ادغامی :
در snapshot//transactional replication ناشران داده ها را ارسال کرده و مشترکین آنها را دریافت می کنند و احتمال اینکه یک مشترک داده های کپی شده را به ناشران ارسال کند ،وجود ندارد اما این امکان به کمک merge replication میسر شده است . Merge replicationنیز همانند transactional replication فعالیت خود را به طور معمول با گرفتن snapshot از اشیا و داده های موجود در پایگاه داده ی یک publication آغاز می کند. تغییرات ثانویه داده ها و نیز تغییرات طرح یا schema در سمت ناشر صورت می گیرد و مشترکین نیز به واسطه ی trigger ها این تغییرات را دنبال می کنند. یک مشترک یا subscriber به هنگام اتصال به شبکه داده های خود را با ناشر تطبیق داده و synchronize می کنند و در واقع به مبادله ی تمامی ردیف هایی که از آخرین عمل synchronization بین ناشر و مشترک دچار تغییر شده اند، می پردازد.Merge replication معمولا برای محیط های سرور به سرویس گیرنده یا Server-to-Client کاربرد دارد وبه کار گیری آن درهریک از شرایط عنوان شده در زیر مناسب است :
- در شرایطی که چندین مشترک ممکن است که داده های مشابه را در زمان های مختلفی بروزرسانی کرده و این تغییرات را برای ناشر و سایر مشترکین منتشر کنند.
- زمانی که مشترکین نیاز به دریافت داده ها و ایجاد تغییرات به صورت آفلاین داشته باشند و بعدا این تغییرات را با ناشر و دیگر مشترکین synchronize کنند.
- هر مشترک به یک پارتیشن متفاوت از داده ها نیاز داشته باشد.
- هنگامیکه ممکن است conflict اتفاق بیفتد و در چنین شرایطی باید قادر به تشخیص و رفع این مشکل باشیم .
Merge replication به سایت های مختلف اجازه می دهد تا به صورت مستقل کار کنند و در نهایت آپدیت ها را بایکدیگر ادغام کرده تا به نتیجه ای یکسان و یکنواخت دست یابند. از آنجایی که به روزرسانی در بیشتر از یک گره صورت می گیرد ، داده های مشابه ممکن است توسط ناشر و نیز بیش از یک مشترک آپدیت شوند بنابراین ممکن است به هنگام ادغام این آپدیت ها تضاد یا conflict اتفاق بیفتد و merge replication راه هایی را برای رسیدگی به مشکل conflict ها فراهم می آورد.
Merge Replication چگونه کار می کند ؟
Merge replication توسط عاملهایی چون snapshot agent و merge agent اجرا می شود. اگر publication یا نشریه فیلتر نشده باشد و یا از فیلترهای استاتیک استفاده می کند ، Snapshot agent تنها یک snapshot ایجاد می کند و اگر که publication از فیلتر های پارامتری یا parameterized filter ها بهره می گیرد ،snapshot agent ازهر پارتیشن داده ها یک snapshot تهیه می کند.merge agent نیز snapshot های اولیه ی تهیه شده را به مشترکین اعمال می کند.این عامل همچنین تغییرات تدریجی که روی داده ها در سمت ناشر و یا مشترکین پس از ایجاد snapshot اولیه صورت گرفته را ادغام کرده وبا توجه به قوانینی که برای آن پیکربندی می کنیم به تشخیص و حل وفصل conflict های ایجاد شده می پردازد. به هنگام استفاده از Merge replication سه تغییر برای ساختار پایگاه داده ی نشریه اتفاق می افتد:
- یک ستون منحصر بفرد را برای هر سطر کپی شده تعیین می کند
- چندین جدول سیستمی اضافه می شود
- Trigger هایی برای جداولی که داده های آنها کپی شده اند،ایجاد می کند.
برای ردیابی تغییرات ، merge replication و نیز transactional replication ای که از قابلیت queued updating استفاده می کند باید قادر به شناساسی هر ردیف از جدول منتشر شده به گونه ای منحصر بفرد باشند. برای انجام این عمل merge replication ستون rowguid را به هر جدول اضافه می کند مگر اینکه جدول در حال حاضر دارای ستونی با نوع داده ی uniqueidentifier و ویژگی ROWGUIDCOL باشد که در این صورت از همین ستون برای شناسایی هر سطر و تغییرات آنها استفاده می شود.
SQL سرور چندین جدول سیستمی برای پشتیبانی از ردیابی داده ها ، انجام عمل synchronization به صورت کارامد و برای تشخیص Conflict ها و نیز برای گزارش دهی ، را به پایگاه داده اضافه می کند.تمامی تغییرات مربوط به داده ها در جداول سیستمی msmerge__contents و msmerge__tombstone ذخیره می شوند. این نوع از replicatin ها trigger هایی را نصب می کند که تغییرات داده های هر ستون و یا هر ردیف از جدول را دنبال می کنند.
trigger ها تغییرات ایجاد شده روی جدول منتشر شده را ضبط کرده و این تغییرات را در جدول های سیستمی msmerge__contents و msmerge__tombstone ثبت می کنند. این trigger ها هنگامی که snapshot agent برای اولین بار برای یک نشریه یا publication اجرا می شود، ایجاد می شوند . trigger ها در سمت یک مشترک نیز هنگامی بوجود می آیند که snapshot برای مشترک استفاده شود. در تصویر زیر اجزایی که درmerge replication به کار گرفته می شوند نمایش داده شده است:

در این مقاله حتی الامکان سعی کردیم به توضیح مفاهیم replication در SQL سرور به زبانی ساده بپردازیم امیدوارم که مورد توجه شما دوستان قرار گیرد.




بدون دیدگاه